
Power BI jest świetnym narzędziem do analizy danych. Dzięki silnikowi Vertipaq, a co za tym idzie – znakomitej wydajności, wyniki zapytań są zwracane bardzo szybko. Szeroka gama wizualizacji zapewnia przejrzystość raportów i dashboardów. Co jednak w sytuacji, kiedy zbiór danych jest na tyle duży, że nie mieści się w pamięci? W takiej sytuacji możemy wspomóc się Composite Modelem i skorzystać z dobrodziejstw Azure Synapse Anlytics.
Czym jest Composite Model w Power BI?
Jak wiadomo, kiedy rozpoczynamy pracę nad modelem, pierwszym krokiem jest przygotowanie jego struktury. Taką strukturę często wypełniamy danymi z zewnętrznego źródła – może nim być np. baza Analysis Services, SQL Server, Azure Synapse Anlytics i wiele, wiele innych. W tym miejscu warto zaznaczyć, że słowo „wypełnić” nie jest zbyt precyzyjne. Dane oczywiście możemy zaimportować do pamięci, dzięki czemu odpytywanie modelu będzie bardzo szybkie, ale pamiętajmy, że pamięć jest ograniczona. W przypadku dużych zbiorów danych nasz model może po prostu nie pomieścić wszystkiego.
Dlatego też istnieje druga opcja dostępu do danych – Direct Query. W tym trybie odpytujemy tabelę bezpośrednio na źródle. Czyli jeśli mamy kilka tabelek opartych o bazę Azure Synapse, to Power BI w pewnym sensie tłumaczy zapytanie DAXowe na SQL i odpytuje bazę. Oczywiście takie rozwiązanie nie będzie tak szybkie jak In-Memory, ale za to nasz model Power BI nie będzie rósł. Przypomnę, że na chwilę pisania tego artykułu mamy do dyspozycji maksymalnie 400 GB pamięci w Power BI Premium. Wydaje się, że to dużo, bo któż ma do dyspozycji 400GB RAMu, natomiast przy naprawdę ogromnych zbiorach może nam tej pamięci zabraknąć.
Mamy też do dyspozycji trzecią opcję, Dual, bedącą hybrydą dwóch powyższych trybów. Composite Model to właśnie możliwość używania różnych źródeł danych w jednym modelu Power BI.
W jaki sposób Azure Synapse może wspomóc model Power BI?
Azure Synapse Analytics (dawniej Azure SQL Data Warehouse), jest usługą, która bardzo dobrze radzi sobie z dużymi zbiorami danych. Mechanizm MPP jest wręcz stworzony do odpytywania i agregowania dużych ilości danych. Pisałem już o tym w jednym z poprzednich artykułów. Co istotne, nie jesteśmy tu ograniczeni tylko do 400 GB, możemy przechowywać znacznie, znacznie więcej danych. No i teraz najważniejsze – Synapse Analytics naprawdę świetnie radzi sobie z agregacją danych. Przy skali miliardów rekordów nie ma problemu, aby zsumować sprzedaż i pogrupować po sklepach czy produktach.
Skoro mamy więc takie możliwości, możemy bez problemu skorzystać z nich w naszym raporcie. Użytkownikom korzystającym z raportów jest wszystko jedno, czy odpytują tabele w trybie Import, czy Direct Query. Ma to po prostu działać wydajnie. Oczywiście zapytania, które będą uruchamiane na Azure Synapse, mogą odpytywać docelową tabelę faktów, ale jak wiemy – im mniejsza tabela, tym łatwiej ją odpytać.
Dlatego też mamy możliwość utworzenia widoków zmaterializowanych. Taki widok, w przeciwieństwie to klasycznego widoku SQL, odkłada dane w pamięci, dzięki czemu nie musimy już wykonywać złączeń czy filtrować rekordów. Dzięki temu może jeszcze bardziej przyspieszyć nasze zapytania. Jest to niemalże idealne rozwiązanie do tworzenia agregacji.
Agregacje - a cóż to takiego?
Zacznijmy od tego, że jest to pewna technika optymalizacyjna. Jeszcze raz przypomnę – im mniej rekordów mamy w tabeli, tym szybciej dostaniemy rezultat zapytania. Teraz wyobraźmy sobie, że w naszym systemie przechowujemy dane sprzedażowe. W tabeli faktu, mamy milion rekordów na poziomie pojedynczego paragonu, a tak się składa, że sprzedajemy tylko 10 różnych. produktów. Nasi użytkownicy codziennie uruchamiają raport i patrzą na jeden produkt. Mimo tego silnik musi przejrzeć te milion rekordów za każdym razem. A co, gdybyśmy zrobili zmaterializowany widok, w którym będziemy mieli zsumowaną sprzedaż, pogrupowaną po produkcie, i taki widok był odpytywany przez użytkowników? Wtedy skanowane było by tylko 10 rekordów! Dzięki temu rezultat będzie zwracany znacznie szybciej. Mało tego, zużyjemy znacznie mniej dostępnych zasobów. Brzmi ciekawie?
Wsparcie Agregacji w PowerBI
Twórcy Power BI, już jakiś czas temu, zauważyli w agregacjach potencjał. W związku z tym dodano do Power BI funkcjonalność, która pozwala obsługiwać tabelki agregacyjne. Sama implementacja jest banalnie prosta. Tworzymy jedną tabelę, która będzie miała dane na najniższym poziomie granularności, czyli na przykład na poziomie paragonu. Ustawiamy ją w trybie Direct Query i łączymy z wymiarami. Następnie dodajemy kolejną tabelę, która będzie miała już zagregowane dane i również łączymy ją z wymiarami. W opcjach ustawiamy, aby była ona traktowana jako tabelka agragacyjna. Teraz piszemy miarę, która będzie sumowała sprzedaż na tabeli z najniższą granularnością. Przy wywołaniu miary Power BI „domyśli się”, że nie musi odpytywać tak dużej tabeli, a może skorzystać z mniejszej. To tyle! Nasz raport powinien teraz znacznie przyspieszyć!
{kind=link}
{kind=link}
Trochę praktyki - czyli nasza strategia
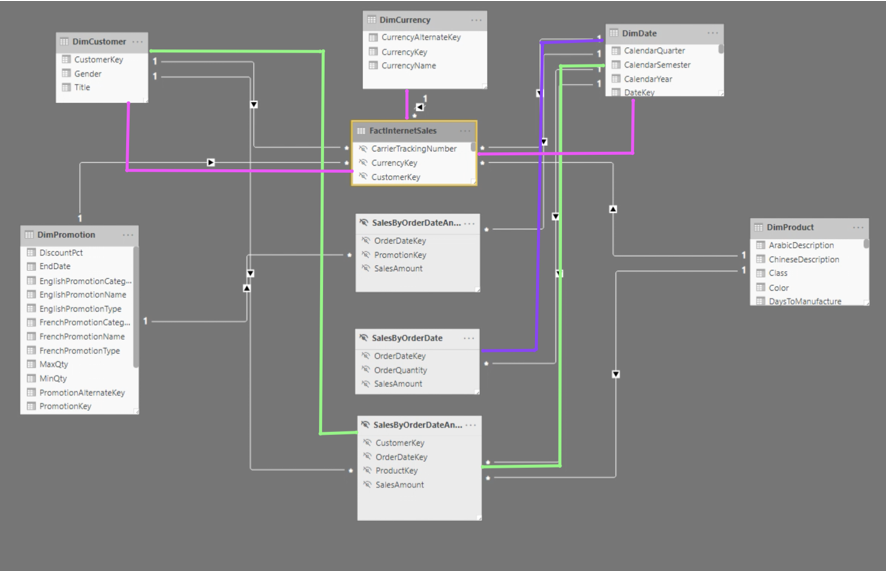
Aby zaprezentować działanie agregacji, Composite Modelu i widoków zmaterializowanych, posłużę się prostym przykładem. Zbudujemy raport oparty na 1 tabeli faktów, 5 tabelach wymiarów i 3 agregacjach. Tabela faktu będzie oparta o Azure Synapse Analytics, a dane będą pobierane w trybie Direct Query. Dwie tabele agregacyjne będą również oparte o Azure Synapse Analytics, natomiast będą to widoki zmaterializowane. Ostatnia tabelka agregacyjna będzie w trybie Import. Po odpowiedniej konfiguracji, widocznej poniżej wszystko powinno działać. Czyli jeśli zechcesz wyświetlać sprzedaż tylko po dacie, silnik odpyta tylko tabelę w trybie Import. Jeżeli zechcesz pogrupować sprzedaż po dacie i promocji, wtedy zostanie odpytany widok zmaterializowany. Jeżeli natomiast chciałbyś zobaczyć w jakiej walucie płacono, silnik zauważy, że aby to zrobić musi niestety odpytać dużą tabelę w Synapse Analytics. Sam opis może wydawać się nieco skomplikowany, ale zasada jest prosta, jeśli jest agregacja, skorzystaj z niej!
{kind=link}
{kind=link}
Łyżka dziegciu
Niestety przedstawione przeze mnie rozwiązanie nie jest odpowiedzią na wszystkie problemy. Jak już pisałem wcześniej, nie zawsze możemy agregować dane. Czasami wymagania co do rozwiązania sprawiają, że nie możemy iść w tym kierunku. Druga sprawa to Azure Synapse Analytics – w tym momencie jesteśmy bardzo mocno ograniczeni, jeśli chodzi o liczbę równoległych zapytań. W najwyższej opcji mamy ich do dyspozycji 128, co oznacza, że przy dużej liczbie użytkowników raport nie będzie działał poprawnie. Osobiście natomiast liczę, że za jakiś czas, ten limit zostanie zdjęty, a wtedy takie rozwiązanie będzie bardzo pomocne. Największa jego zaleta to fakt, że nie trzeba przechowywać starych danych w modelu Power BI. Możemy je mieć w naszej hurtowni, dzięki czemu dostęp do danych bieżących będzie bardzo szybki, a jeśli ktoś będzie chciał odpytać dane historyczne – też będzie mógł to zrobić, choć nieco wolniej. Oczywiście możemy podłączyć się do jakiegoś innego źródła niż Azure Synapse Analytics, natomiast to już rozważania na osobny artykuł.
Jeszcze więcej praktyki!
Jako, że temat jest nieco zawiły, postanowiłem nagrać film, na którym krok po kroku opisuję jak wykorzystać agregacje i Composite Model w swoim modelu Power BI. Zapraszam do oglądania!
Jeszcze trochę materiałów...
Jeśli zainteresował Cię temat agregacji samych w sobie, to u Philipa Seamarka znajdziesz świetną serię artykułów na temat agregacji. Warto zapoznać się też z filmem związanym z tym tematem lub odwiedzić bloga seequality, gdzie znajduje się bardzo fajny post dotyczący agregacji w Power BI.