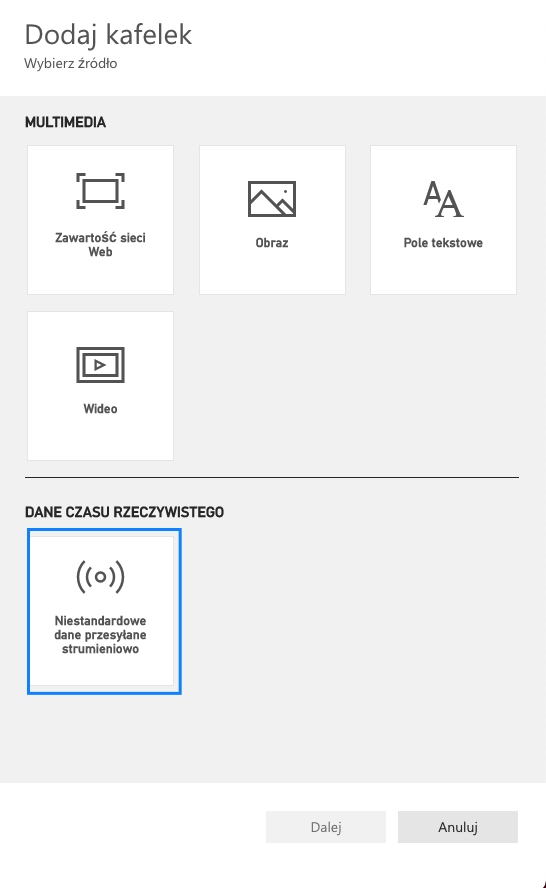
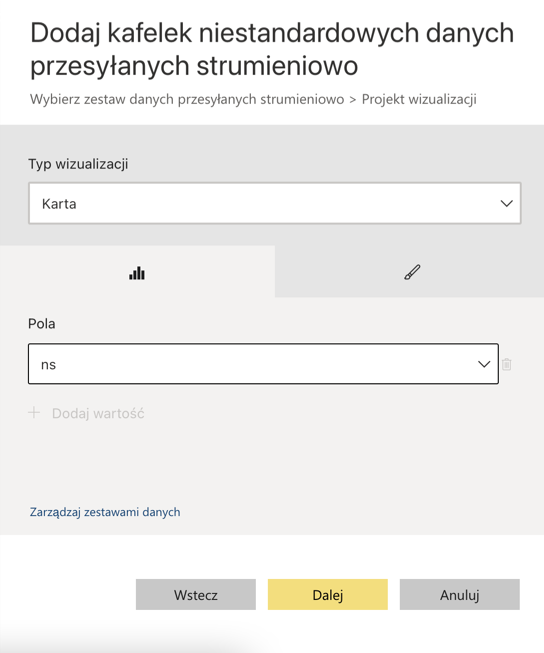
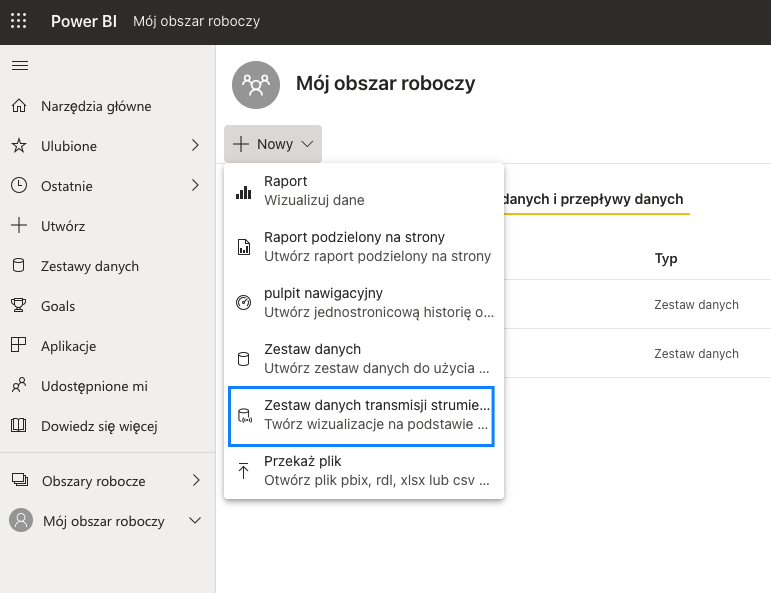
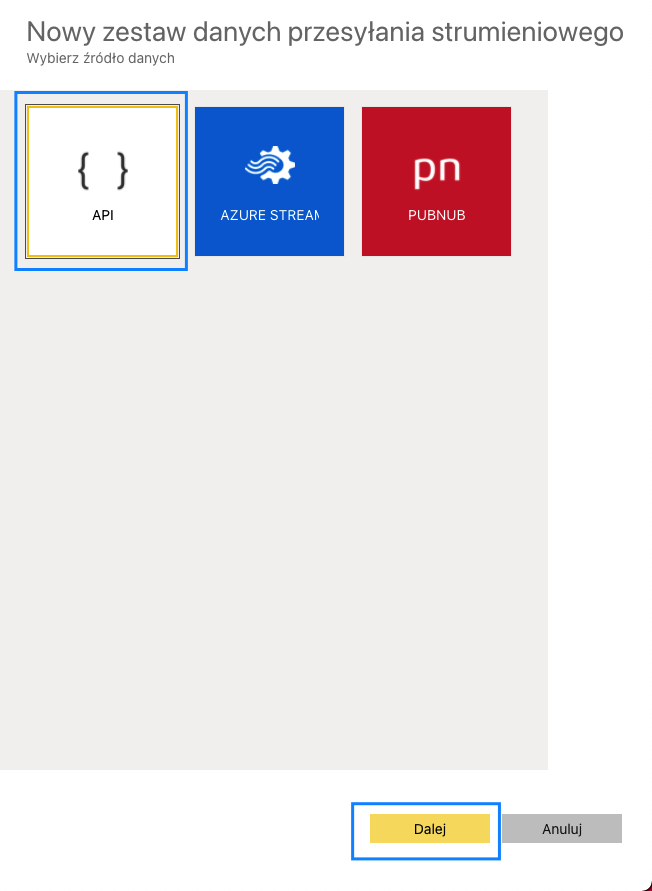
Power BI Service oferuje obsługę danych strumieniowych, a do dyspozycji mamy dwa typy datasetów. Pierwszy z nich to Push Dataset. Czym różni się od klasycznego datasetu? Możemy tam ładować dane za pośrednictwem API oraz tworzyć nowe obiekty, np. tabele czy relacje. Co to oznacza w praktyce? Mianowicie jesteśmy w stanie zbudować model danych wykorzystując tylko i wyłącznie API, a także ładować do niego dane. To znaczy, że w możemy napisać kod w pythonie, który będzie tworzył nowe tabele w modelu danych. Następnie jesteśmy w stanie utworzyć streaming w databricksach, który będzie ładował dane bezpośrednio do tabel modelu.
W odróżnieniu od klasycznego podejścia tutaj ładujemy dane, a nie pobieramy je ze źrodła podczas procesowania. Takie rozwiązanie ma oczywiście pewne ograniczenia, które można sprawdzić tutaj. Oznacza to, że nie może być traktowane jako równorzędne z analitycznymi bazami danych. Jakie mogą być potencjalne przypadki użycia? Proste modele z niewielką liczbą rekordów, którymi chcemy zarządzać z poziomu kodu. Warto zaznaczyć, że aby taki model obsługiwać potrzebne jest dodatkowe konto techniczne z licencją pro.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}